1
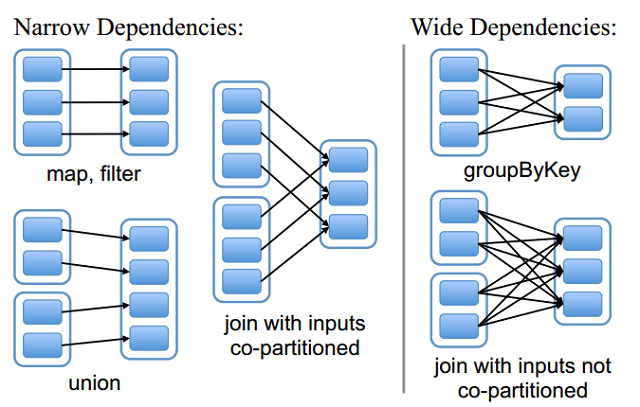
私はいくつかのパーティション化戦略、特に2つのRDDSを共同してパーティション化し、それらを結合し、それらに対してreduce操作を呼び出すことによってPySparkコードを最適化しようとしています(それより複雑ですが、モデル)。中の図を見るとスパーク・ジョインが効率的な共用入力ジョインであることをどのように知ることができますか?
:
img http://reactivesoftware.pl/spark/img/rdd_dependency.png
{kind=link}
共同パーティションは、非常に効率的かつスキニーで参加します。私の質問は、私のjoin/reduceが正しく分割されていることをどのように知っているのですか? SparkアプリケーションのUIにはどのような統計情報が必要ですか?どのようなパフォーマンスの改善が見込まれますか?データが適切にスパークで共分割されていない場合は、システムはシャッフルを実行するために持っている
ありがとう、あなたのコメント> "あなたは最小限の読み込みとゼロの書き込みを見なければなりません"私が探していたものです。あなたの最後のポイントは、rddがすでに分割されている場合、reduceByKeyは単なるローカルなリダクションであり、シャッフルは含まれません。 –
@Camパーティションに特定のキーのデータセットが含まれている場合はyesですが、十分に大きなSparkデータセットの場合は、複数のパーティションにわたって1つのキーの値を分割します(つまり、キー "A"パーティション1,2、および3)を使用して、いくつかの並列性の利点を得ることができます。 –